Reward function specification can be difficult, even in simple environments. Rewarding the agent for making a widget may be easy, but penalizing the multitude of possible negative side effects is hard. In toy environments, Attainable Utility Preservation (AUP) avoided side effects by penalizing shifts in the ability to achieve randomly generated goals. We scale this approach to large, randomly generated environments based on Conway’s Game of Life. By preserving optimal value for a single randomly generated reward function, AUP incurs modest overhead while leading the agent to complete the specified task and avoid side effects.
Experiments
In Conway’s Game of Life, cells are alive or dead. Depending on how many live neighbors surround a cell, the cell comes to life, dies, or retains its state. Even simple initial conditions can evolve into complex and chaotic patterns.
SafeLife turns the Game of Life into an actual game. An autonomous agent moves freely through the world, which is a large finite grid. In the eight cells surrounding the agent, no cells spawn or die – the agent can disturb dynamic patterns by merely approaching them. There are many colors and kinds of cells, many of which have unique effects.
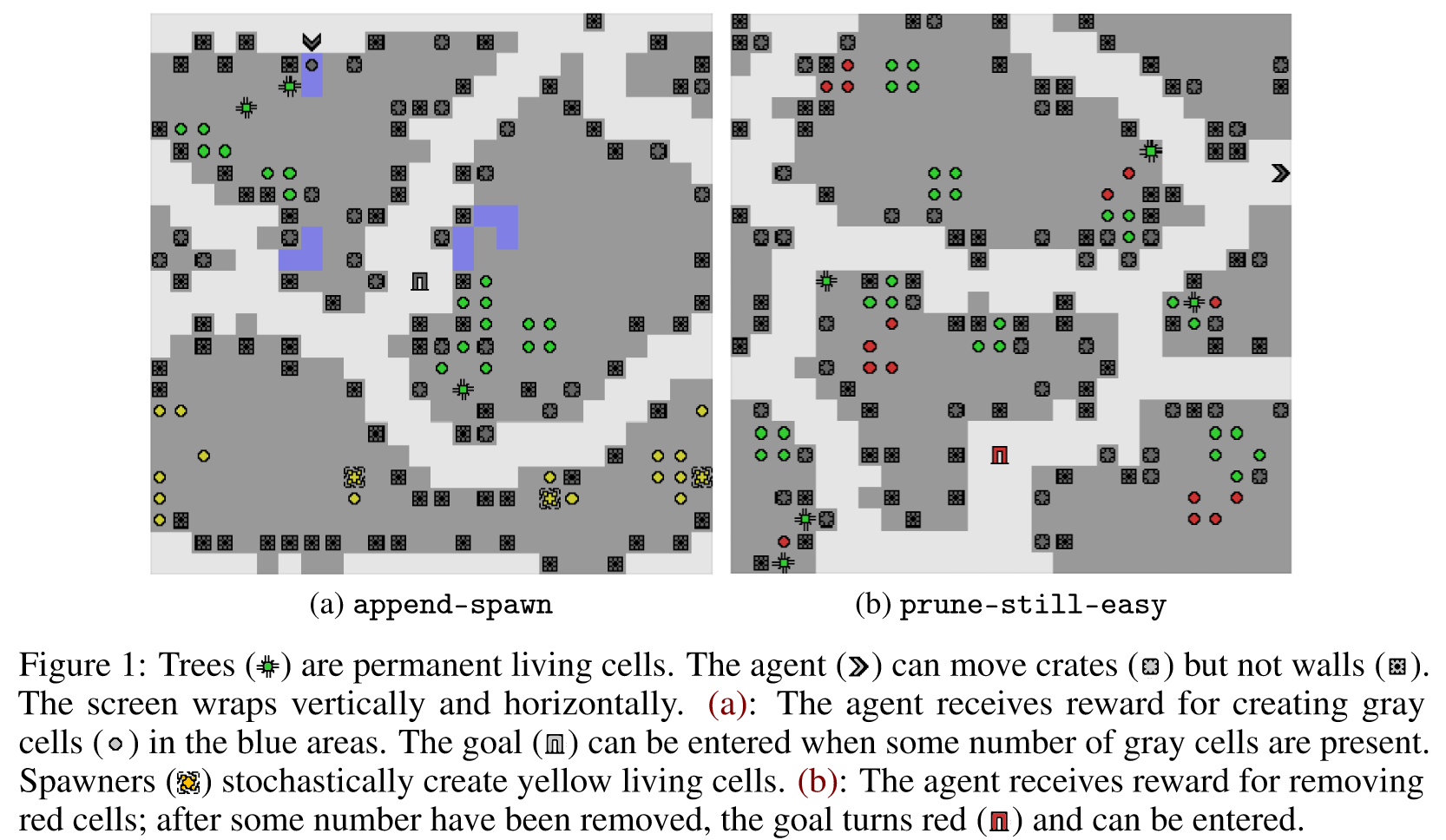
As the environment only rewards pruning red cells or creating gray cells in blue tiles, unpenalized RL agents often make a mess of the green cells. The agent should “leave a small footprint” by not disturbing unrelated parts of the state, such as the green cells. Roughly, SafeLife measures side effects as the degree to which the agent disturbs green cells.
For each of the four following tasks, we randomly generate four curricula of 8 levels each. For two runs from each task, we randomly sample a trajectory from the baseline and AUP policy networks. We show side-by-side results below; for quantitative results, see our paper.
The following demonstrations were uniformly randomly selected; they are not cherry-picked. The original SafeLife reward is shown in green (more is better), while the side effect score is shown in orange (less is better). The “Baseline” condition is trained to only optimize the original SafeLife reward.
prune-still-easy
The agent is rewarded for destroying red cells. After enough cells are destroyed, the agent may exit the level.
append-still-easy
The agent is rewarded for creating gray cells on light blue tiles. After enough gray cells are present on blue tiles, the agent may exit the level.
AUP’s first trajectory temporarily stalls, before finishing the episode after the video’s 14-second cutoff. AUP’s second trajectory does much better.
append-still
append-still-easy, but with more green cells.
In the first demonstration, both AUP and the baseline stall out after gaining reward. AUP clearly beats the baseline in the second demonstration.
append-spawn
append-still-easy, but with noise generated by stochastic yellow spawners.